

¿Qué es AWS Lambda?

AWS Lambda es un servicio en la nube basado en funciones que elimina las necesidades de aprovisionamiento y mantenimiento de una infraestructura compleja («Sin Servidores»). Con Lambda, no necesitamos preocuparnos por escalar nuestra infraestructura y eliminar recursos innecesarios, ya que todo esto se maneja de manera paralela.
Ventajas de AWS Lambda
Muchas de las ventajas de usar AWS Lambda se relacionan con las ventajas de adoptar el enfoque Sin Servidores en general. Uno de los principales beneficios de no tener servidor es el tiempo y el esfuerzo que se ahorra al crear y mantener la infraestructura necesaria. AWS aprovisiona y administra la infraestructura en las que se ejecutan sus funciones de Lambda, escala las instancias para sortear los tiempos de carga excesiva e implementa el registro y el manejo de errores adecuadamente.
El tiempo ahorrado significa un tiempo de desarrollo más rápido para su aplicación, una mayor agilidad a medida que el equipo puede hacerlo más rápido y más tiempo dedicado a tareas más importantes, como la corrección de errores o nuevas funciones.
En cuanto a por qué AWS Lambda es una de las soluciones sin servidores más populares, AWS ha hecho un muy buen trabajo al garantizar que Lambda se adapte a las aplicaciones a escala, así como a las aplicaciones en las primeras etapas. Además AWS permite ejecutar nuestra función Lambda simultáneamente con otras funciones Lambda; es decir, no tendremos que preocuparnos por las colas atascadas. Podemos aprovisionar y ejecutar varias instancias de la misma función Lambda al mismo tiempo.
¿Cómo funciona AWS Lambda?
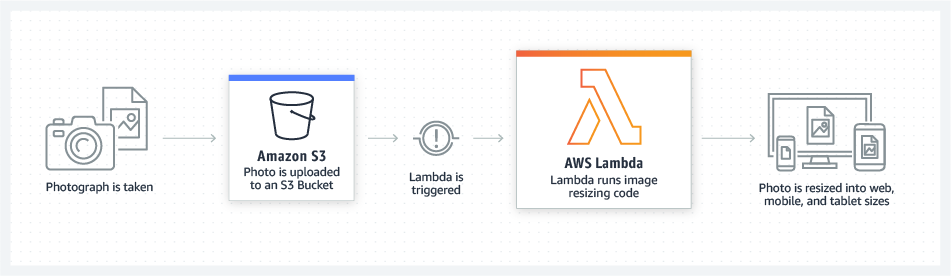
Si no estás familiarizado con los servicios ServerLess y has llegado hasta aquí, es posible que tengas la sensación de que todo esto te suena a chino; pero si has decidido apostar por Lambda, entonces, ya has recorrido la mitad del camino. El siguiente paso es conocer cómo funciona y comprender su mecanismo interno.
Si lo resumimos a un nivel muy básico, las aplicaciones se componen de 2 ó 3 componentes. Tenemos una fuente de eventos, funciones y servicios.
Fuente de eventos
Una fuente de eventos encapsula cualquier cosa que requiera de una función, como cargas a un depósito de S3, cambios en el estado de los datos o solicitudes a un punto final. Cuando ocurre cualquiera de los eventos designados, la función Lambda se ejecutará en su propio contenedor. Los recursos asignados a ese contenedor y la cantidad de contenedores utilizados están determinados por el tamaño de los datos y los requisitos computacionales de la función. Todo esto lo maneja AWS. Una vez que se completa la solicitud, la función Lambda devolverá un resultado a la fuente de la llamada, servicio conectado, o puede realizar cambios en un servicio conectado (como una base de datos).
Si tenemos estos conceptos claros, el siguiente paso es crear una función Lambda. Esta consta de 3 ó 4 partes; la función de controlador, el objeto de evento, el objeto de contexto y, en algunos casos, una función de devolución de llamada.
El controlador
La función del controlador es la función que se ejecutará al momento de la llamada y puede ser asíncrona o no asíncrona. Las funciones asincrónicas toman un objeto de evento y un objeto de contexto, mientras que las funciones no asincrónicas toman estos objetos y una función de devolución de llamada. El objeto de evento contiene datos que se enviaron cuando se activó el evento de la función, esto incluye información como el cuerpo de la solicitud y el uri; los datos que se transmiten dependen del servicio de llamada de datos.
Ya por último, el objeto de contexto contiene información de tiempo de ejecución, como el nombre de la función, su versión y el grupo de registro. La función de devolución de llamada solo se pasa a los controladores síncronos y toma dos argumentos: un error y una respuesta. Una vez que se crea la función Lambda y se envía a AWS, se comprime junto con sus dependencias y se almacena en un bucket de S3.
const fetchData = require('./fetch.js')
exports.handler = async (event, context) => {
return await fetchData(event, context)
}
exports.handler = function(event, context, callback) {
try {
// your code would go here
callback(null, res)
} catch(err) {
callback(err)
}
}
Para los controladores no asíncronos, la ejecución de la función continúa hasta que el bucle de eventos está vacío o la función agota el tiempo de espera.
Capas
Una vez que comienzas a construir tus primeras funciones Lambda, notarás que hay piezas de lógica que podrían compartirse entre múltiples funciones, aquí es cuando las capas pueden resultar útiles.
Las capas permiten reutilizar código en varias funciones sin necesidad de una llamada adicional. Una capa se crea de la misma manera que una función Lambda, con ligeros cambios de configuración que dependen del método elegido para implementar las funciones (a través de la GUI de AWS, utilizando el marco sin servidor o la herramienta CLI de AWS).
Versiones y alias
AWS no solo permite guardar diferentes versiones de nuestras funciones, sino que también permite que estas versiones coexistan y se ejecuten al mismo tiempo. Esto brinda la posibilidad de actualizar a versiones más nuevas cuando lo necesitemos.
Para simplificar el proceso, los alias se utilizan como un puntero a una versión particular de una función Lambda. En lugar de actualizar la versión de una función en todos los lugares a los que se llama, podemos usar un alias en estas áreas y actualizar la versión a la que apunta el alias.
Permisos
Los permisos que rodean a las funciones de Lambda se dividen en dos grupos: políticas de ejecución y políticas basadas en recursos. Las políticas de ejecución determinan a qué servicios y recursos tiene acceso una función de Lambda, así como qué fuentes de eventos pueden activar la ejecución de una función de Lambda. Las políticas basadas en recursos otorgan acceso a otras cuentas y servicios de AWS a sus recursos de Lambda, que incluyen funciones, versiones, alias y versiones de capas.
Resiliencia
AWS ayuda a garantizar que las funciones Lambda puedan lidiar con fallos sin afectar a toda su aplicación mediante un conjunto de características que han incluido en Lambda. Las características más notables son la escalabilidad, el control de versiones y la capacidad de Lambda para ejecutarse simultáneamente.
Pero si hablamos de resiliencia, también existen un par de características adicionales, como el uso de múltiples zonas de disponibilidad y la capacidad de reservar simultaneidad. De forma predeterminada, AWS ejecuta sus funciones de Lambda en varias zonas de disponibilidad, esto asegura que no se vean afectadas si una sola zona está inactiva. Con Lambda, los desarrolladores tienen la capacidad de establecer simultaneidad reservada para una función en particular, lo que garantiza que siempre se pueda escalar una cantidad determinada de llamadas simultáneas a pesar de la cantidad de solicitudes.
Conclusión
Y llegamos al final de este artículo. Existe una gran cantidad de casos de uso en los que las funciones de AWS Lambda pueden ser de mucha utilidad. Podemos crear operaciones de procesamiento o tareas de automatización que no requieran de un servidor completo funcionando en todo momento. Si pensamos en Lambda como las piezas de un set de Lego, las posibilidades son infinitas.
¿NECESITAS ASESORÍA?
Conéctate con un experto




